Adversarial infill
The problem
I’ve had a lot of time on my hands recently, because my internet has been broken. During that time, I wanted to become familiar with pyTorch, because it’s neat. I’m also very interested in GANs and adversarial learning in general. I always have trouble getting adversarial learning to work, it’s quite fiddly, with entire pages devoted to tips and tricks, including that the GAN objective everyone writes about is not the one they use. So, with that in mind, I wanted to take the complexity down a notch, by writing an “adversarial infiller”, that takes an image with a part missing, and fills in that missing part.
The code
You can check out the code on github.
I use luigi to manage the task structure. It’s also presented little cleaner here than in the repo - that’s just because I played around with a few ideas before settling on this approach. Happy reading!
The network
The generator
The generator takes an image with a hole in it, and tries to fill in the hole:
INPUT
+--------------+
| |
| +----+ | +----+
| |????| | --> | |
| +----+ | +----+
| |
+--------------+
The image is a four channel image. The fourth channel is set to 1 in the missing section, and zero elsewhere.
The network is quite small and simple
class Generator(torch.nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.conv1 = nn.Conv2d(4, 64, 5, padding=3)
self.conv2 = nn.Conv2d(64, 128, 7)
self.conv3 = nn.Conv2d(128, 128, 3)
self.conv4 = nn.Conv2d(128, 3, 3)
def forward(self, x, missing):
x = torch.cat([x, missing], 1)
x = nn.LeakyReLU()(self.conv1(x))
x = nn.LeakyReLU()(self.conv2(x))
x = nn.LeakyReLU()(self.conv3(x))
x = nn.LeakyReLU()(self.conv4(x))
return xThe x is the image, and the missing is the fourth channel mentioned above.
The discriminator
The disciminator simply takes entire image (both the patch and the context it came from), and predicts whether or not it is real or generated (1 or 0)
It’s quite simple as well:
class Checker(torch.nn.Module):
def __init__(self):
super(Checker, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 5)
self.l1 = nn.Linear(64, 32)
self.l2 = nn.Linear(32, 1)
def forward(self, x):
x = nn.MaxPool2d(2)(nn.LeakyReLU()(self.conv1(x)))
x = nn.MaxPool2d(2)(nn.LeakyReLU()(self.conv2(x)))
size = x.size()
x = x.view(size[0], size[1]*size[2]*size[3])
x = nn.LeakyReLU()(self.l1(x))
x = nn.Sigmoid()(self.l2(x))
return xSide note on pytorch
I’ve found pytorch to be easier to use than tensorflow. Because the graph is built dynamically, it’s a lot easer to debug and fiddle with. I can add print statements to parts of the code, for example.. Never underestimate the debugging power of a well placed print statement.
One thing that did trip me up: pytorch totally lets you do numpy style assignment like this:
mat[4:6] = [1,2]
however, this will not propate gradients. Instead, you need to concatenate the data:
mat_new = torch.cat([mat[:4], [1,2], mat[6:]], 0)
Training
To train the code, I basically built two optimizers:
generator = Generator()
checker = Checker()
generator_opt = optim.Adam(generator.parameters())
checker_opt = optim.Adam(checker.parameters())And then optimized the binary cross entropy, with the appropriate ones and zeros:
- When training the generator train with all ones. We want the generator to make good samples, so we teach it to trick the discriminator.
- When training the discriminator, train with ones for true cases, and zeros for generated, because we’re teaching it to discriminate between generator and real values.
def make_mats():
generator.zero_grad()
checker.zero_grad()
gen = generator(x, missing)
# di has a bunch of info on the sizes of the image
# patches.
top = x[:, :, :di.l, :]
bottom = x[:, :, di.r:, :]
left = x[:, :, di.l:di.r, :di.l]
right = x[:, :, di.l:di.r, di.r:]
mid_g = torch.cat([left, gen, right], 3)
mid_y = torch.cat([left, y, right], 3)
x_g = torch.cat([top, mid_g, bottom], 2)
x_y = torch.cat([top, mid_y, bottom], 2)
discrims_g = checker(x_g)
discrims_y = checker(x_y)
return x_g, x_y, discrims_g, discrims_y
x_e, x_y, discrims_g, discrims_y = make_mats()
generator_opt_loss = \
torch.nn.BCELoss()(discrims_g, Variable(torch.ones(self.batch_size))) + \
torch.nn.BCELoss()(discrims_y, Variable(torch.ones(self.batch_size)))
generator_opt_loss.backward()
generator_opt.step()
x_e, x_y, discrims_g, discrims_y = make_mats()
gen_opt_loss = \
torch.nn.BCELoss()(discrims_g, Variable(torch.zeros(self.batch_size))) + \
torch.nn.BCELoss()(discrims_y, Variable(torch.ones(self.batch_size)))
gen_opt_loss.backward()
checker_opt.step()Results
It works better than I expected! I trained it on a dataset of images of flowers.
Here’s some samples from the start. The system does poorly:
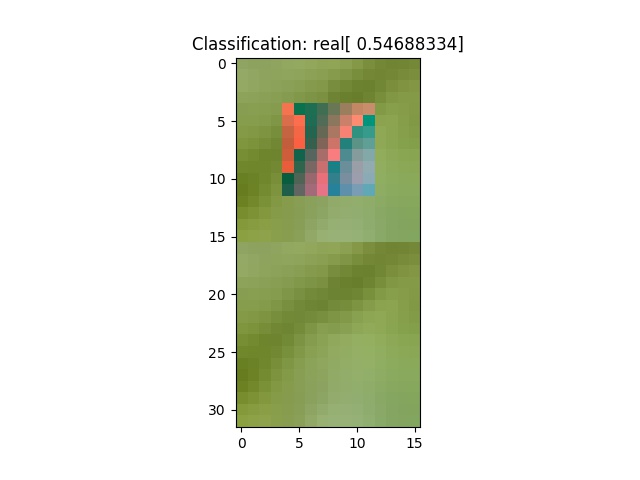
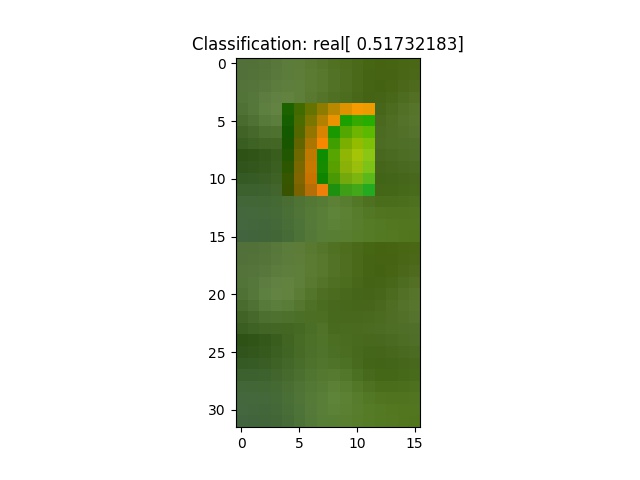
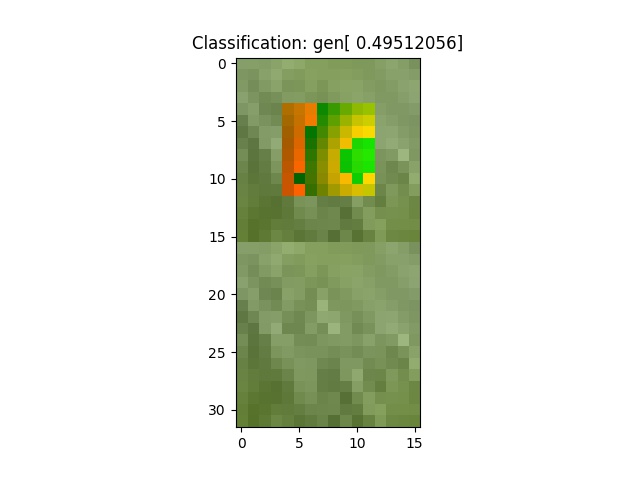
And from the end, at training batch 4000
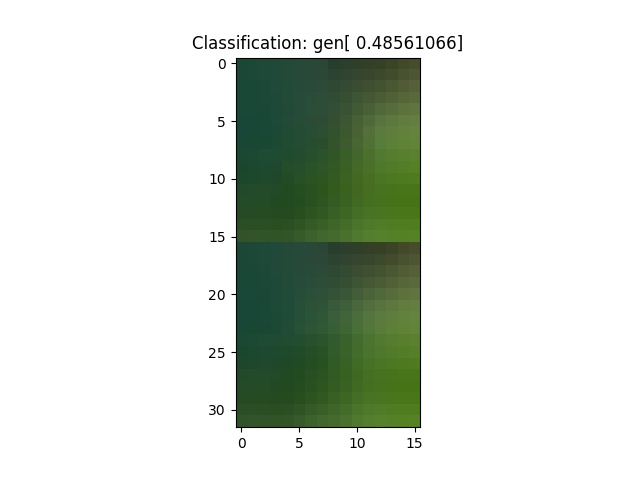
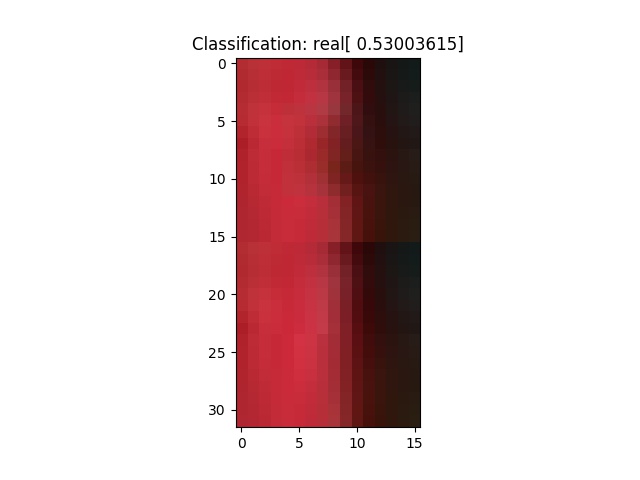
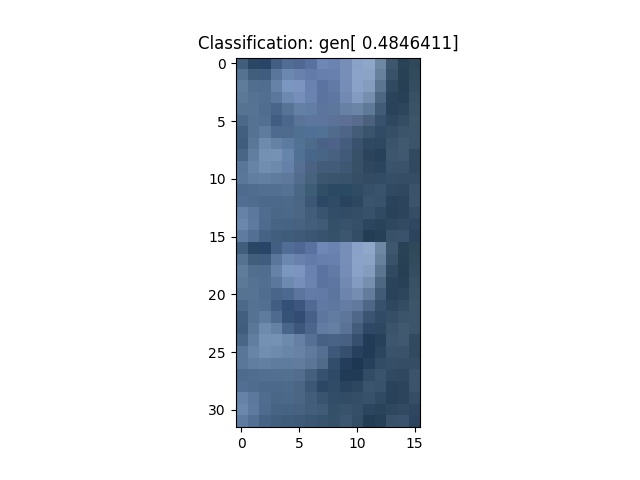
The main complaint I have with these results is that they’re a little bit blurry.
And sometimes it just goes nuts and gets everything wrong. Here’s one I found around batch 4000:
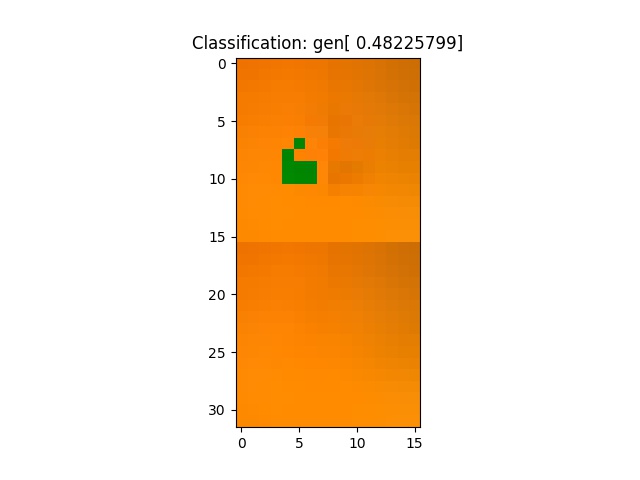
Conclusion
This approach worked quite well! I’m going to try scaling it up. I don’t have access to a big GPU, which limits my ability to do these sorts of experiments, but maybe it’s time for a new GPU :). Thanks for reading!